Rask mønstermatching av strenger ved hjelp av Suffix Tree i Java
1. Oversikt
I denne opplæringen vil vi utforske konseptet med mønstermatching av strenger og hvordan vi kan gjøre det raskere. Deretter går vi gjennom implementeringen i Java.
2. Mønster Matching av strenger
2.1. Definisjon
I strenger er mønstermatching prosessen med å sjekke for en gitt sekvens av tegn som kalles et mønster i en sekvens av tegn kalt a tekst.
De grunnleggende forventningene til mønstermatching når mønsteret ikke er et vanlig uttrykk er:
- kampen skal være nøyaktig - ikke delvis
- resultatet skal inneholde alle kamper - ikke bare den første kampen
- resultatet bør inneholde plasseringen av hver kamp i teksten
2.2. Søker etter et mønster
La oss bruke et eksempel for å forstå et enkelt mønstermatchingsproblem:
Mønster: NA Tekst: HAVANABANANA Match1: ---- NA ------ Match2: -------- NA-- Match3: ---------- NAVi kan se at mønsteret NA forekommer tre ganger i teksten. For å få dette resultatet kan vi tenke å skyve mønsteret ett tegn om gangen nedover teksten og se etter en kamp.
Dette er imidlertid en brute-force tilnærming med tidskompleksitet O (p * t) hvor s er mønsterets lengde, og t er lengden på teksten.
Anta at vi har mer enn ett mønster å søke etter. Deretter øker tidskompleksiteten også lineært, ettersom hvert mønster trenger en separat iterasjon.
2.3. Trie datastruktur for å lagre mønstre
Vi kan forbedre søketiden ved å lagre mønstrene i en triedatastruktur, som er kjent for sin raske gjenopprettingtrieverdi av gjenstander.
Vi vet at en triedatastruktur lagrer tegnene til en streng i en trelignende struktur. Så for to strenger {NA, NAB}, får vi et tre med to stier:

Å ha en trie opprettet gjør det mulig å skyve en gruppe mønstre nedover teksten og se etter treff i bare en iterasjon.
Legg merke til at vi bruker $ tegn for å indikere slutten på strengen.
2.4. Suffiks Trie Datastruktur for å lagre tekst
EN suffiks triederimot er en trie datastruktur konstruert ved hjelp av alle mulige suffikser av en enkelt streng.
For forrige eksempel HAVANABANANA, kan vi lage et suffiks:

Suffiksforsøk blir laget for teksten og gjøres vanligvis som en del av et forbehandlingstrinn. Etter det kan du søke etter mønstre raskt ved å finne en sti som samsvarer med mønstersekvensen.
Imidlertid er det kjent at et suffiks trie bruker mye plass ettersom hvert tegn i strengen er lagret i en kant.
Vi ser på en forbedret versjon av suffiks-trie i neste avsnitt.
3. Suffiksetre
Et suffiks tre er rett og slett en komprimert suffiks trie. Hva dette betyr er at ved å bli med kantene kan vi lagre en gruppe tegn og derved redusere lagringsplassen betydelig.
Så vi kan lage et suffiks-tre for den samme teksten HAVANABANANA:

Hver sti som starter fra roten til bladet representerer et suffiks av strengen HAVANABANANA.
Et suffiksetre også lagrer posisjonen til suffikset i bladnoden. For eksempel, BANANA $ er et suffiks som starter fra den syvende posisjonen. Derfor vil verdien være seks ved å bruke nullbasert nummerering. Like måte, A-> BANANA $ er et annet suffiks som begynner på posisjon fem, som vi ser på bildet ovenfor.
Så når vi setter ting i perspektiv, kan vi se det et mønstermatch samsvarer når vi klarer å få en sti som starter fra rotnoden med kanter som stemmer overens med det gitte mønsteret posisjonelt.
Hvis stien ender ved en bladnode, får vi et suffiks. Ellers får vi bare en substringkamp. For eksempel mønsteret NA er et suffiks av HAVANABANA [NA] og et underlag av HAVA [NA] BANANA.
I neste avsnitt vil vi se hvordan du implementerer denne datastrukturen i Java.
4. Datastruktur
La oss lage en suffiks-datastruktur. Vi trenger to domeneklasser.
For det første trenger vi en klasse for å representere treknuten. Det må lagre treets kanter og barnets noder. I tillegg, når det er en bladnode, må den lagre posisjonsverdien til suffikset.
Så la oss lage våre Node klasse:
offentlig klasse Node {privat strengtekst; private List barn; privat int stilling; offentlig node (strengord, int-posisjon) {this.text = word; denne.posisjon = posisjon; this.children = new ArrayList (); } // getters, setters, toString ()}For det andre trenger vi en klasse for å representere treet og lagre rotnoden. Det må også lagre fullteksten som suffikser genereres fra.
Derfor har vi en SuffixTree klasse:
offentlig klasse SuffixTree {private static final String WORD_TERMINATION = "$"; privat statisk slutt int POSITION_UNDEFINED = -1; privat Node-rot; privat streng fulltekst; offentlig SuffixTree (strengtekst) {root = new Node ("", POSITION_UNDEFINED); fulltekst = tekst; }}5. Hjelpemetoder for å legge til data
Før vi skriver kjernelogikken vår for å lagre data, la oss legge til noen hjelpemetoder. Disse vil vise seg nyttige senere.
La oss endre vår SuffixTree klasse for å legge til noen metoder som trengs for å konstruere treet.
5.1. Legge til en undernode
For det første, la oss ha en metode addChildNode til legge til en ny undernode til en gitt foreldrenode:
privat tomrom addChildNode (Node parentNode, String text, int index) {parentNode.getChildren (). add (new Node (text, index)); }5.2. Finne lengste vanlige prefiks med to strenger
For det andre skriver vi en enkel verktøymetode getLongestCommonPrefix til finn det lengste vanlige prefikset med to strenger:
private String getLongestCommonPrefix (String str1, String str2) {int CompareLength = Math.min (str1.length (), str2.length ()); for (int i = 0; i <CompareLength; i ++) {if (str1.charAt (i)! = str2.charAt (i)) {return str1.substring (0, i); }} returner str1.substring (0, sammenlignLengde); }5.3. Splitting a Node
For det tredje, la oss ha en metode for å skjære ut en barneknute fra en gitt foreldre. I denne prosessen er foreldrenoden tekst verdien blir avkortet, og den høyre avkortede strengen blir tekst verdien av undernoden. I tillegg blir foreldrene til barna overført til barnekoden.
Vi kan se på bildet under det ANA blir delt til A-> NA. Etterpå, det nye suffikset ABANANA $ kan legges til som A-> BANANA $:

Kort sagt, dette er en praktisk metode som vil være nyttig når du setter inn en ny node:
privat ugyldig splitNodeToParentAndChild (Node parentNode, String parentNewText, String childNewText) {Node childNode = new Node (childNewText, parentNode.getPosition ()); if (parentNode.getChildren (). size ()> 0) {while (parentNode.getChildren (). size ()> 0) {childNode.getChildren () .add (parentNode.getChildren (). remove (0)); }} parentNode.getChildren (). legg til (childNode); parentNode.setText (parentNewText); parentNode.setPosition (POSITION_UNDEFINED); }6. Hjelpermetode for gjennomgang
La oss nå lage logikken for å krysse treet. Vi bruker denne metoden til både å konstruere treet og søke etter mønstre.
6.1. Partial Match vs. Full Match
La oss først forstå konseptet med en delvis kamp og en full kamp ved å vurdere et tre befolket med noen få suffikser:

For å legge til et nytt suffiks ANABANANA $, sjekker vi om det finnes noen node som kan endres eller utvides for å imøtekomme den nye verdien. For dette sammenligner vi den nye teksten med alle nodene og finner ut at den eksisterende noden [A] VANABANANA $ kamper ved første karakter. Så dette er noden vi trenger å endre, og denne kampen kan kalles en delvis samsvar.
På den annen side, la oss vurdere at vi søker etter mønsteret VANE på samme tre. Vi vet at det delvis samsvarer med [VAN] ABANANA $ på de tre første tegnene. Hvis alle de fire tegnene hadde matchet, kunne vi kalle det en full kamp. For mønstersøk er en fullstendig samsvar nødvendig.
Så for å oppsummere, vil vi bruke en delvis kamp når du konstruerer treet og en full samsvar når vi søker etter mønstre. Vi bruker et flagg isAllowPartialMatch for å indikere hvilken kamp vi trenger i hvert tilfelle.
6.2. Traversing the Tree
La oss nå skrive vår logikk for å krysse treet så lenge vi er i stand til å matche et gitt mønster posisjonelt:
Liste getAllNodesInTraversePath (strengmønster, node startNode, boolsk isAllowPartialMatch) {// ...}Vi kaller dette rekursivt og returnerer en liste over alle noder finner vi i vår vei.
Vi begynner med å sammenligne mønstertekstens første tegn med nodeteksten:
if (pattern.charAt (0) == nodeText.charAt (0)) {// logikk for å håndtere gjenværende tegn} For en delvis samsvar, hvis mønsteret er kortere eller like langt til nodeteksten, legger vi til den nåværende noden i vår noder liste opp og stopp her:
if (isAllowPartialMatch && pattern.length () <= nodeText.length ()) {nodes.add (currentNode); retur noder; } Deretter sammenligner vi de resterende tegnene i denne nodeteksten med mønsteret. Hvis mønsteret har en posisjonsforskjell med nodeteksten, stopper vi her. Den nåværende noden er inkludert i noder liste bare for en delvis kamp:
int CompareLength = Math.min (nodeText.length (), mønster.length ()); for (int j = 1; j <CompareLength; j ++) {if (pattern.charAt (j)! = nodeText.charAt (j)) {if (isAllowPartialMatch) {nodes.add (currentNode); } returnere noder; }} Hvis mønsteret samsvarer med nodeteksten, legger vi den nåværende noden til vår noder liste:
nodes.add (currentNode);Men hvis mønsteret har flere tegn enn nodeteksten, må vi sjekke undernodene. For dette ringer vi et rekursivt anrop som passerer currentNode som startnode og gjenværende del av mønster som det nye mønsteret. Listen over noder som returneres fra denne samtalen er lagt til vår noder listen hvis den ikke er tom. I tilfelle det er tomt for et fullstendig kampscenario, betyr det at det var en uoverensstemmelse, så for å indikere dette, legger vi til et null punkt. Og vi returnerer noder:
if (pattern.length ()> CompareLength) {List nodes2 = getAllNodesInTraversePath (pattern.substring (CompareLength), currentNode, isAllowPartialMatch); hvis (nodes2.size ()> 0) {nodes.addAll (nodes2); } annet hvis (! isAllowPartialMatch) {nodes.add (null); }} returner noder;Setter alt dette sammen, la oss lage getAllNodesInTraversePath:
privat liste getAllNodesInTraversePath (strengmønster, node startNode, boolsk isAllowPartialMatch) {Listnoder = ny ArrayList (); for (int i = 0; i <startNode.getChildren (). størrelse (); i ++) {Node currentNode = startNode.getChildren (). get (i); Streng nodeText = currentNode.getText (); if (pattern.charAt (0) == nodeText.charAt (0)) {if (isAllowPartialMatch && pattern.length () <= nodeText.length ()) {nodes.add (currentNode); retur noder; } int CompareLength = Math.min (nodeText.length (), pattern.length ()); for (int j = 1; j CompareLength) {List nodes2 = getAllNodesInTraversePath (pattern.substring (CompareLength), currentNode, isAllowPartialMatch); hvis (nodes2.size ()> 0) {nodes.addAll (nodes2); } annet hvis (! isAllowPartialMatch) {nodes.add (null); }} returner noder; }} returner noder; }7. Algoritme
7.1. Lagring av data
Vi kan nå skrive logikken vår for å lagre data. La oss starte med å definere en ny metode addSuffix på SuffixTree klasse:
privat tomrom addSuffix (streng suffiks, int posisjon) {// ...}Den som ringer vil oppgi suffikset.
Deretter la oss skrive logikken for å håndtere suffikset. Først må vi sjekke om det eksisterer en bane som delvis samsvarer med suffikset i det minste ved å ringe vår hjelpemetode getAllNodesInTraversePath med isAllowPartialMatch angitt som ekte. Hvis det ikke finnes noen sti, kan vi legge til suffikset vårt som barn til roten:
Liste noder = getAllNodesInTraversePath (mønster, rot, sant); hvis (nodes.size () == 0) {addChildNode (rot, suffiks, posisjon); }Derimot, Hvis en bane eksisterer, betyr det at vi må endre en eksisterende node. Denne noden vil være den siste i noder liste. Vi må også finne ut hva som skal være den nye teksten for denne eksisterende noden. Hvis den noder listen har bare ett element, så bruker vi suffiks. Ellers ekskluderer vi det vanlige prefikset opp til den siste noden fra suffiks å få ny tekst:
Node lastNode = nodes.remove (nodes.size () - 1); String newText = suffiks; if (nodes.size ()> 0) {String existingSuffixUptoLastNode = nodes.stream () .map (a -> a.getText ()) .reduce ("", String :: concat); newText = newText.substring (eksisterendeSuffixUptoLastNode.length ()); }For å endre den eksisterende noden, la oss lage en ny metode utvide noden, som vi ringer fra der vi slapp addSuffix metode. Denne metoden har to hovedansvar. Den ene er å bryte opp en eksisterende node til foreldre og barn, og den andre er å legge til et barn i den nyopprettede foreldrenoden. Vi bryter opp foreldrenoden bare for å gjøre den til en felles node for alle underordnede noder. Så den nye metoden vår er klar:
privat ugyldig extensionNode (Node node, String newText, int posisjon) {String currentText = node.getText (); String commonPrefix = getLongestCommonPrefix (currentText, newText); if (commonPrefix! = currentText) {String parentText = currentText.substring (0, commonPrefix.length ()); String childText = currentText.substring (commonPrefix.length ()); splitNodeToParentAndChild (node, parentText, childText); } Streng gjenværende tekst = ny tekst.substring (commonPrefix.length ()); addChildNode (node, gjenværende tekst, posisjon); }Vi kan nå komme tilbake til metoden vår for å legge til et suffiks, som nå har all logikken på plass:
privat tomrom addSuffix (streng suffiks, int posisjon) {List noder = getAllNodesInTraversePath (suffiks, root, true); hvis (nodes.size () == 0) {addChildNode (rot, suffiks, posisjon); } annet {Node lastNode = nodes.remove (nodes.size () - 1); String newText = suffiks; if (nodes.size ()> 0) {String existingSuffixUptoLastNode = nodes.stream () .map (a -> a.getText ()) .reduce ("", String :: concat); newText = newText.substring (eksisterendeSuffixUptoLastNode.length ()); } extendNode (lastNode, newText, position); }}Til slutt, la oss endre vår SuffixTree konstruktør for å generere suffikser og kalle vår forrige metode addSuffix for å legge dem iterativt til datastrukturen vår:
offentlig ugyldig SuffixTree (strengtekst) {root = new Node ("", POSITION_UNDEFINED); for (int i = 0; i <text.length (); i ++) {addSuffix (text.substring (i) + WORD_TERMINATION, i); } fulltekst = tekst; }7.2. Søker etter data
Etter å ha definert vår suffiks-trestruktur for å lagre data, vi kan nå skrive logikken for å utføre søket vårt.
Vi begynner med å legge til en ny metode søkTekst på SuffixTree klasse, tar i mønster for å søke som en inngang:
public List searchText (Strengmønster) {// ...}Deretter for å sjekke om mønster finnes i suffiksetreet vårt, kaller vi vår hjelpemetode getAllNodesInTraversePath med flagget satt for eksakte treff bare, i motsetning til når vi la til data når vi tillot delvis samsvar:
Liste noder = getAllNodesInTraversePath (mønster, rot, falsk);Vi får deretter listen over noder som samsvarer med mønsteret vårt. Den siste noden i listen indikerer noden som mønsteret matchet nøyaktig med. Så vårt neste trinn vil være å få alle bladnodene som stammer fra denne siste matchende noden og få posisjonene lagret i disse bladnodene.
La oss lage en egen metode getPosisjoner å gjøre dette. Vi vil sjekke om den gitte noden lagrer den siste delen av et suffiks for å avgjøre om posisjonsverdien må returneres. Og vi vil gjøre dette rekursivt for hvert barn i den gitte noden:
private List getPositions (Node node) {List positions = new ArrayList (); if (node.getText (). endsWith (WORD_TERMINATION)) {positions.add (node.getPosition ()); } for (int i = 0; i <node.getChildren (). size (); i ++) {positions.addAll (getPositions (node.getChildren (). get (i))); } returposisjoner; }Når vi har settet med posisjoner, er neste trinn å bruke det til å markere mønstrene på teksten vi lagret i suffiksetreet. Posisjonsverdien indikerer hvor suffikset starter, og lengden på mønsteret indikerer hvor mange tegn som skal forskyves fra startpunktet. Ved å bruke denne logikken, la oss lage en enkel verktøymetode:
private String markPatternInText (Integer startPosition, String pattern) {String matchingTextLHS = fullText.substring (0, startPosition); Streng matchingText = fullText.substring (startPosisjon, startPosisjon + mønster.lengde ()); String matchingTextRHS = fullText.substring (startPosisjon + mønsterlengde ()); return matchingTextLHS + "[" + matchingText + "]" + matchingTextRHS; }Nå har vi våre støttemetoder klare. Derfor, vi kan legge dem til i vår søkemetode og fullføre logikken:
public List searchText (String pattern) {List result = new ArrayList (); Liste noder = getAllNodesInTraversePath (mønster, root, false); hvis (nodes.size ()> 0) {Node lastNode = nodes.get (nodes.size () - 1); if (lastNode! = null) {List positions = getPositions (lastNode); posisjoner = posisjoner. strøm (). sortert (). samle (Collectors.toList ()); positions.forEach (m -> result.add ((markPatternInText (m, mønster)))); }} returner resultat; }8. Testing
Nå som vi har algoritmen på plass, la oss teste den.
La oss først lagre en tekst i vår SuffixTree:
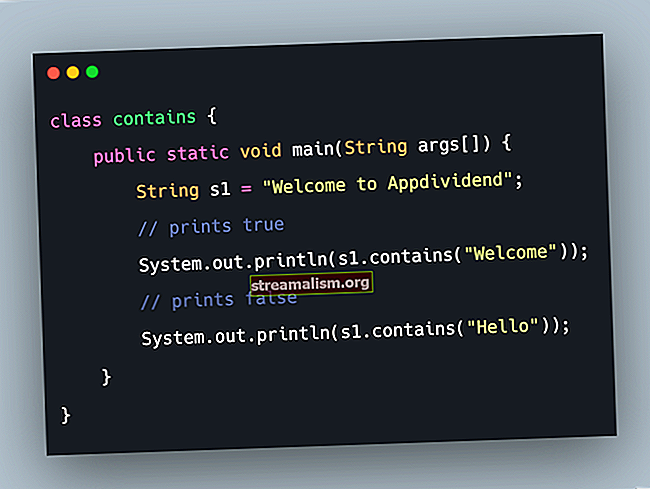
SuffixTree suffixTree = ny SuffixTree ("havanabanana"); La oss deretter søke etter et gyldig mønster en:
Listetreff = suffiksTree.searchText ("a"); matches.stream (). forEach (m -> LOGGER.info (m));Å kjøre koden gir oss seks kamper som forventet:
h [a] vanabanana hav [a] nabanana havan [a] banana havanab [a] nana havanaban [a] na havanabanan [a]Neste, la oss søk etter et annet gyldig mønster nab:
Listetreff = suffiksTree.searchText ("nab"); matches.stream (). forEach (m -> LOGGER.info (m)); Å kjøre koden gir oss bare en kamp som forventet:
hava [nab] ananaTil slutt, la oss søk etter et ugyldig mønster gnage:
Listetreff = suffiksTree.searchText ("nag"); matches.stream (). forEach (m -> LOGGER.info (m));Å kjøre koden gir oss ingen resultater. Vi ser at fyrstikker må være eksakte og ikke delvis.
Dermed har mønstersøkealgoritmen vår vært i stand til å tilfredsstille alle forventningene vi la ut i begynnelsen av denne opplæringen.
9. Tidskompleksitet
Når du konstruerer suffiksetreet for en gitt lengdetekst t, den tidskompleksitet er O (t).
Deretter for å søke etter et lengdemønster p,tidskompleksiteten er O (p). Husk at det var et søk etter brute-force O (p * t). Og dermed, mønstersøk blir raskere etter forbehandling av teksten.
10. Konklusjon
I denne artikkelen forsto vi først konseptene til tre datastrukturer - trie, suffiks trie og suffiks tre. Vi så hvordan et suffiksetre kunne brukes til å kompakt lagre suffikser.
Senere så vi hvordan vi kunne bruke et suffiks-tre til å lagre data og utføre et mønstersøk.
Som alltid er kildekoden med tester tilgjengelig på GitHub.