Introduksjon til Apache Spark
1. Introduksjon
Apache Spark er et open source klyngedatamiljø. Det gir elegante utviklings-API-er for Scala, Java, Python og R som tillater utviklere å utføre en rekke data-intensive arbeidsbelastninger på tvers av forskjellige datakilder, inkludert HDFS, Cassandra, HBase, S3 etc.
Historisk viste Hadoops MapReduce seg å være ineffektiv for noen iterative og interaktive databehandlinger, noe som til slutt førte til utviklingen av Spark. Med Spark kan vi kjøre logikk opp til to størrelsesordener raskere enn med Hadoop i minnet, eller en størrelsesorden raskere på disken.
2. Gnistarkitektur
Gnistapplikasjoner kjører som uavhengige prosess sett i en klynge som beskrevet i diagrammet nedenfor:

Disse prosessene koordineres av SparkContext objekt i hovedprogrammet ditt (kalt driverprogrammet). SparkContext kobles til flere typer klyngebehandlere (enten Sparks egen frittstående klyngesjef, Mesos eller YARN), som fordeler ressurser på tvers av applikasjoner.
Når den er koblet til, anskaffer Spark eksekutører på noder i klyngen, som er prosesser som kjører beregninger og lagrer data for applikasjonen din.
Deretter sender den applikasjonskoden din (definert av JAR- eller Python-filer sendt til SparkContext) til utførerne. Endelig, SparkContext sender oppgaver til eksekutørene for å kjøre.
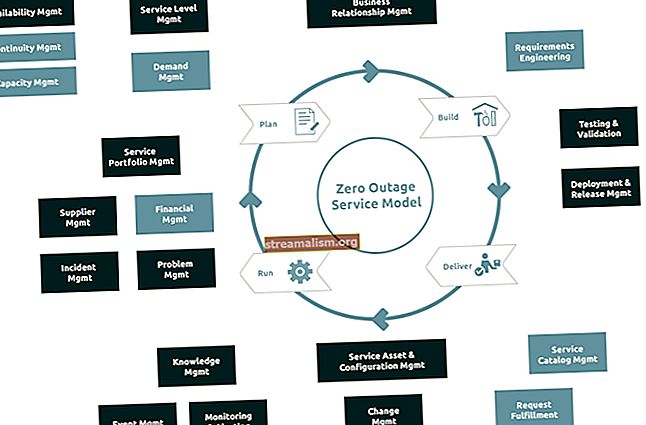
3. Kjernekomponenter
Følgende diagram gir et klart bilde av de forskjellige komponentene i Spark:

3.1. Gnistkjerne
Spark Core-komponenten er ansvarlig for alle de grunnleggende I / O-funksjonene, planlegging og overvåking av jobbene på gnistklynger, oppgaveutsending, nettverk med forskjellige lagringssystemer, feilgjenoppretting og effektiv minnestyring.
I motsetning til Hadoop, unngår Spark delte data som skal lagres i mellombutikker som Amazon S3 eller HDFS ved å bruke en spesiell datastruktur kjent som RDD (Resilient Distribuerte datasett).
Resilient Distribuerte datasett er uforanderlige, en partisjonert samling av poster som kan opereres - parallelt og tillater - feiltolerante 'in-memory' beregninger.
RDD støtter to typer operasjoner:
- Transformasjon - Spark RDD-transformasjon er en funksjon som produserer ny RDD fra eksisterende RDD. Transformatoren tar RDD som inngang og produserer en eller flere RDD som utgang. Transformasjoner er lat i naturen, dvs. de blir utført når vi kaller en handling
- Handling – transformasjoner skaper RDD-er fra hverandre, men når vi ønsker å jobbe med det faktiske datasettet, utføres det på det tidspunktet handling. Og dermed, Handlinger er Spark RDD-operasjoner som gir verdier som ikke er RDD. Handlingsverdiene er lagret til drivere eller til det eksterne lagringssystemet
En handling er en av måtene å sende data fra Executor til sjåføren.
Eksekutører er agenter som er ansvarlige for å utføre en oppgave. Mens sjåføren er en JVM-prosess som koordinerer arbeidstakere og utførelse av oppgaven. Noen av handlingene til Spark teller og samles.
3.2. Gnist SQL
Spark SQL er en Spark-modul for strukturert databehandling. Den brukes primært til å utføre SQL-spørsmål. Dataramme utgjør den viktigste abstraksjonen for Spark SQL. Distribuert innsamling av data bestilt i navngitte kolonner er kjent som en Dataramme i Spark.
Spark SQL støtter henting av data fra forskjellige kilder som Hive, Avro, Parquet, ORC, JSON og JDBC. Den skaleres også til tusenvis av noder og flere timers spørsmål ved bruk av Spark-motoren - som gir full feiltoleranse i midten av spørringen.
3.3. Spark Streaming
Spark Streaming er en utvidelse av kjernen Spark API som muliggjør skalerbar, høy gjennomstrømning, feiltolerant strømbehandling av live datastrømmer. Data kan tas inn fra en rekke kilder, for eksempel Kafka-, Flume-, Kinesis- eller TCP-stikkontakter.
Til slutt kan bearbeidede data skyves ut til filsystemer, databaser og live dashboards.
3.4. Spark Mlib
MLlib er Sparks bibliotek for maskinlæring (ML). Målet er å gjøre praktisk maskinlæring skalerbar og enkel. På høyt nivå gir den verktøy som:
- ML-algoritmer - vanlige læringsalgoritmer som klassifisering, regresjon, klynging og samarbeidsfiltrering
- Featurization - funksjonsutvinning, transformasjon, dimensjonsreduksjon og utvalg
- Rørledninger - verktøy for å konstruere, evaluere og justere ML-rørledninger
- Persistens - lagrings- og lastalgoritmer, modeller og rørledninger
- Verktøy - lineær algebra, statistikk, datahåndtering etc.
3.5. Spark GraphX
GraphX er en komponent for grafer og graf-parallelle beregninger. På et høyt nivå utvider GraphX Spark RDD ved å introdusere en ny Graph-abstraksjon: en rettet multigraph med egenskaper knyttet til hvert toppunkt og kant.
For å støtte grafberegning eksponerer GraphX et sett med grunnleggende operatører (f.eks. subgraf, joinVertices, og aggregateMessages).
I tillegg inkluderer GraphX en voksende samling av grafalgoritmer og byggere for å forenkle grafanalyseoppgaver.
4. “Hello World” i Spark
Nå som vi forstår kjernekomponentene, kan vi gå videre til enkelt Maven-basert Spark-prosjekt - for beregning av antall ord.
Vi vil demonstrere Spark som kjører i lokal modus der alle komponentene kjører lokalt på samme maskin der det er masternoden, eksekveringsnodene eller Sparks frittstående klyngebehandler.
4.1. Maven Setup
La oss sette opp et Java Maven-prosjekt med Spark-relaterte avhengigheter i pom.xml fil:
org.apache.spark spark-core_2.10 1.6.0 4.2. Antall ord - Spark Job
La oss nå skrive Spark-jobb for å behandle en fil som inneholder setninger og sende ut forskjellige ord og deres tellinger i filen:
offentlig statisk ugyldig hoved (String [] args) kaster Unntak {if (args.length <1) {System.err.println ("Bruk: JavaWordCount"); System.exit (1); } SparkConf sparkConf = ny SparkConf (). SetAppName ("JavaWordCount"); JavaSparkContext ctx = ny JavaSparkContext (sparkConf); JavaRDD linjer = ctx.textFile (args [0], 1); JavaRDD-ord = lines.flatMap (s -> Arrays.asList (SPACE.split (s)). Iterator ()); JavaPairRDD-ens = ord.mapToPair (ord -> ny Tuple2 (ord, 1)); JavaPairRDD teller = ones.reduceByKey ((Heltall i1, Heltall i2) -> i1 + i2); Liste output = count.collect (); for (Tuple2 tuple: output) {System.out.println (tuple._1 () + ":" + tuple._2 ()); } ctx.stop (); } Legg merke til at vi passerer banen til den lokale tekstfilen som et argument til en Spark-jobb.
EN SparkContext objektet er det viktigste inngangspunktet for Spark og representerer tilkoblingen til en allerede kjørende Spark-klynge. Det bruker SparkConf objekt for å beskrive applikasjonskonfigurasjonen. SparkContext brukes til å lese en tekstfil i minnet som en JavaRDD gjenstand.
Deretter transformerer vi linjene JavaRDD motsette seg ord JavaRDD objektet ved hjelp av flatmap metode for først å konvertere hver linje til mellomromsseparerte ord og deretter flate utdataene for hver linjebehandling.
Vi bruker igjen transformasjonsoperasjon mapToPair som i utgangspunktet kartlegger hver forekomst av ordet til ordet og antall 1.
Deretter bruker vi redusereByKey operasjon for å gruppere flere forekomster av et hvilket som helst ord med telling 1 til en mengde ord og oppsummerte tellingen.
Til slutt utfører vi cvalg RDD-handling for å få de endelige resultatene.
4.3. Utfører - Spark Job
La oss nå bygge prosjektet ved hjelp av Maven for å generere apache-spark-1.0-SNAPSHOT.jar i målmappen.
Deretter må vi sende denne WordCount-jobben til Spark:
$ {spark-install-dir} / bin / spark-submit --class com.baeldung.WordCount - master local $ {WordCount-MavenProject} /target/apache-spark-1.0-SNAPSHOT.jar $ {WordCount-MavenProject} /src/main/resources/spark_example.txtGnistinstallasjonskatalog og WordCount Maven-prosjektkatalog må oppdateres før du kjører over kommandoen.
Etter innsending skjer det noen trinn bak kulissene:
- Fra førerkoden, SparkContext kobles til klyngebehandler (i vårt tilfelle gnist frittstående klyngesjef som kjører lokalt)
- Cluster Manager fordeler ressurser på tvers av de andre applikasjonene
- Spark anskaffer eksekutører på noder i klyngen. Her vil vår ordtelling-applikasjon få sine egne utførelsesprosesser
- Søknadskode (jar-filer) sendes til utførere
- Oppgaver sendes av SparkContext til utførerne.
Til slutt blir resultatet av gnistjobben returnert til driveren, og vi vil se antall ord i filen som utdata:
Hei 1 fra 2 Baledung 2 Keep 1 Learning 1 Spark 1 Bye 15. Konklusjon
I denne artikkelen diskuterte vi arkitekturen og forskjellige komponenter i Apache Spark. Vi demonstrerte også et fungerende eksempel på en Spark-jobb som gir ordtelling fra en fil.
Som alltid er hele kildekoden tilgjengelig på GitHub.